INTRODUCTION
청능사는 청자의 의사소통 능력을 예측하기 위해 조용한 상황 혹은 소음 상황에서 어음인지 능력을 측정한다. 청자가 일상에서 자주 접하는 듣기 환경은 다양한 소음이 있는 환경이기 때문에, 청각검사 시 여러 소리 음원이 서로 다른 위치에서 제시되는 조건 혹은 다양한 소음을 배경소음으로 제시하는 조건 등을 활용할 수 있다(Francart et al., 2011; King et al., 2020; Wagener & Brand, 2005).
다양한 선행 연구에서 소음의 특성 및 강도, 소음의 위치 등의 여러 요소가 청자의 소음 하 어음인지에 영향을 준다고 보고하였다(Middlebrooks, 2017; Takahashi & Bacon, 1992; Hawley et al., 2004). 특히 목표 음원과 소음이 서로 다른 위치에서 제시되는 경우 음원 간 위치 분리가 소음 하 어음인지에 긍정적인 영향을 주며, 이를 위치 분리 혜택(spatial separation benefit, SSB) 혹은 spatial release from masking이라 명명하였다(Hawley et al., 2004; King et al., 2020; Yost, 2017). 건청인과 난청인을 대상으로 SSB를 측정한 결과 두 대상군 모두 긍정적인 SSB를 보였으며, 전반적으로 건청인에 비해 난청인의 SSB 정도가 더 적었다(Marrone et al., 2008; Van Deun et al., 2010).
소음 하 검사 시 변동 소음(fluctuating masker) 환경에서 목표 어음을 제시할 경우 어음과 소음이 시간에 따라 모두 변동하는 특성을 가지는데, 어음의 강도가 소음의 강도보다 더 커지는 순간마다 어음의 정보를 접할 수 있는 기회가 생겨 소음 하 어음 인지가 용이하게 된다. 이와 같이 소음의 변동 특성을 통해 어음 인지가 더 향상한다는 점을 고려하여 연구자들은 이를 변동 소음 혜택(fluctuating masker benefit, FMB) 혹은 masking release from masker-fluctuation이라 부르거나(Festen & Plomp, 1990; Jensen & Bernstein, 2019), 소음보다 어음의 강도가 더 커서 목표 어음의 정보를 엿보는 기회가 된다는 점을 강조하여 glimpsing이라 명명하였다(Cooke, 2006; Edraki et al., 2022; Li & Loizou, 2007; Miller et al., 2018).
변동 소음이 배경소음으로 제시된 경우 변동 비율, 깊이, 유형, 소음의 대역폭 및 강도 등과 같은 특성들이 청자의 FMB에 영향을 준다(Festen & Plomp, 1990; Fogerty et al., 2016; Fogerty et al., 2018; Wagener et al., 2006). 난청인의 경우 건청인에 비해 비교적 적은 FMB를 보이거나 FMB가 아예 관찰되지 않기도 하였는데(Eisenberg et al., 1995; Hall et al., 2012; Jensen & Bernstein, 2019; Wagener et al., 2006), 난청인의 청력 상태 혹은 역치상 시간해상 능력(Dubno et al., 2003; Festen & Plomp, 1990; George et al., 2006; Summers & Molis, 2004; Takahashi & Bacon, 1992) 등이 FMB에 복합적으로 영향을 줄 수 있다고 하였다.
우리가 일상생활에서 접하는 소음 하 의사소통 상황은 여러 방향에서 목표 화자와 배경소음이 위치하거나 변동 소음이 배경 소음으로 제시되는 환경이다. 헤드폰 혹은 한 개의 음장 스피커만을 이용하는 청각 임상 환경에서는 대상자가 소음 하 의사소통 시 음원 위치 분리로 인하여 혜택을 받을 수 있는지, 변동 소음의 특성을 활용하여 소음 하 인지가 향상될 수 있는지 파악하기 어렵다. Collin & Lavandier(2013)은 음원 간 위치 분리와 변동 소음의 특성이 소음 하 어음인지에 개별적으로 영향을 주며, 건청인과 난청인의 인지에 미치는 영향도 다를 수 있다고 하였다. Hawley et al.(2004) 역시 음원 간 위치 분리 여부나 소음의 종류가 양이 청취의 효과를 측정하는데 많은 영향을 준다고 하였다. 따라서 본 연구에서는 음원 간 위치 분리(목표 문장과 소음을 정면에서 동시 제시, 30° 위치 분리, 60° 위치 분리)와 소음 종류(비변동 소음, 변동률을 달리한 변동 소음), 신호대소음비(signal-to-noise ratio, SNR)가 건청인과 난청인의 소음 하 어음인지도에 미치는 영향을 확인하고자 하였다.
MATERIALS AND METHODS
연구 대상
본 연구에는 건청인 20명(남 13명, 여 7명), 난청인 10명(남 7명, 여 3명), 총 30명의 대상자가 참여하였다. 건청군(normal-hearing group, NH)의 평균 연령은 24.00세(SD, 3.80; range, 19~30세)였고, NH 대상자 모두 순음청력검사 결과 양 귀 250~8,000 Hz 이내 옥타브 단위 주파수에서 20 dB HL 미만의 순음청력역치를 보였으며, 어음청각검사 결과 보통대화레벨인 65 dB sound pressure level (SPL)에서 어음 제시 시 95% 이상의 단어인지도, 문장인지도를 보였다.
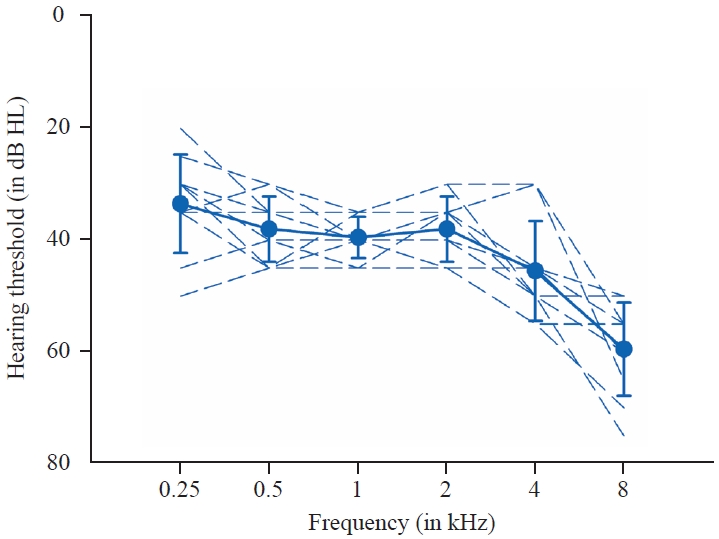
난청군(hearing-impaired group, HI)의 평균 연령은 74.50세였고(SD, 5.02; range, 64~80세), 세계보건기구 청력손실 등급(World Health Organization-proposed hearing-impairment grade)에 기준하였을 때(Humes, 2019) HI 대상자 모두 양이 모두 중도(moderate) 혹은 중고도 난청(moderately severe)을 보였다. HI 대상자의 보청기 착용 전 우측 귀의 500, 1,000, 2,000 Hz 주파수 평균순음역치는 평균 46.33 ± 9.19 dB HL, 좌측 귀의 경우 평균 50.38 ± 7.12 dB HL이었다. HI 대상자 10명 중 7명은 양이의 평균순음역치 차이가 10 dB 이내의 대칭형 양이 난청을 보였다. 음장검사를 통해 측정한 보청기 착용 후 500, 1,000, 2,000 Hz 주파수의 평균순 음역치는 평균 38.50 dB HL (SD, 3.80; range, 31.67~45.00 dB HL), 500, 1,000, 2,000, 4,000 Hz 주파수에서의 고주파수 평균순음역치는 평균 41.00 dB HL (SD, 5.04; range, 31.67~46.67 dB HL)이었다. 보통대화레벨인 65 dB SPL에서 어음을 제시하고 보청기 착용 후 음장 어음청각검사를 시행한 결과 평균 단어인지도는 77.80% (SD, 11.61; range, 64~95%), 평균 문장인지도는 90.80% (SD, 7.53; range, 80~100%)로 HI 대상자 10명 모두 소음이 없는 조건에서 80% 이상의 문장인지도를 보임을 확인하였다. Figure 1은 250~8,000 Hz 내 옥타브 단위 주파수에서 보청기 착용 후 측정한 HI 대상자의 개인별 순음청력역치 및 평균을 보여준다.
청력검사기(AudioStar pro; Grason-Stadler, Eden Prairie, MN, USA)와 헤드폰(TDH-39P; Telephonics, Farmingdale, NY, USA)을 통해 순음청력검사와 어음청각검사를 시행하였다. 대상자 모두 이경을 통한 육안 관찰 시 외이 및 고막에 이상이 없었으며, 임피던스 청력 검사 기기(Resonance R25C; Resonance, Gazzaniga, Italy)를 이용하여 고막운동도를 관찰한 결과 양이 모두 A형 고막운동성을 보였다. 연구 참여자 모두 이과 및 신경학적 병력이 없었으며, 연구에 참여하기 전 대상자들에게 본 연구의 목적, 방법 및 진행 절차에 대한 설명을 제공하였으며 참여자들의 동의 후에 연구를 진행하였다.
연구 절차
본 연구에서는 목표 문장으로 한국어 Matrix 소음 하 문장을 제시하였다(Kim & Lee, 2018). 한국어 Matrix 소음 하 문장은 10 × 5 행렬(matrix)에 포함된 50개의 단어 중 5개 단어를 무작위로 조합하여 문장을 생성하므로 모든 문장의 구조가 동일하다는 특징을 가진다. 문장 내 단어를 외워서 대답하기 어렵다는 장점이 있어 반복적으로 문장인지도 측정이 필요한 연구에서 유용하게 사용할 수 있다. 본 연구에서 한국어 Matrix 문장검사 시 10개의 Matrix 문장으로 구성된 문장 목록을 각 듣기 조건에 사용하였고, 본 연구의 배경소음은 MATLAB 소프트웨어(R2016b; The Mathworks, Inc., Natick, MA, USA)로 제작하여 사용하였다. 비변동 소음으로 한국어 Matrix 문장의 장기평균어음스펙트럼을 가진 어음스펙트럼 소음(speechshaped noise, SSN)을 제작하여 사용하였다. 변동 소음으로는 정현 곡선을 따라 진폭이 변조되고 100%의 변동 깊이(modulation depth)를 가지며(sinusoidally amplitudemodulated noise, SAM), Figure 2에 나타낸 것처럼 2 Hz, 4 Hz, 8 Hz의 변동률(modulation rate)을 가지도록 제작하였다. 변동률을 고려하여 본 연구에서 이를 각각 SAM02, SAM04, SAM08이라고 명명하였다.
모든 실험은 국제 표준에서 권고하는 소음허용수준(International Organization for Standardization, 2012)을 만족하는 방음실에서 실시하였다. 대상자에게 목표 문장과 소음이 정면 방향(0°)의 스피커에서 함께 제시되는 조건(colocated)과 목표 문장과 소음의 음원 간 위치 분리가 있는 조건에서 소음 하 어음인지도를 측정하였다. 위치 분리가 있는 조건의 경우 목표 문장은 정면에서, 소음은 대상자의 보청기 착용 후 평균순음역치가 더 좋은 귀 방향 30°에 위치한 스피커를 통해 제시하는 조건(spatially separated by 30°), 마지막으로 문장은 정면에서, 소음은 좋은 귀 방향 60°에 위치한 스피커를 통해 소음을 제시하는 조건(spatially separated by 60°), 총 세 가지 듣기 조건에서 실험을 진행하였다. 모든 스피커(SC-M53; DENON, Kawasaki, Japan)는 대상자의 귀 높이에 1미터 거리에 정면(0°) 혹은 좌측 혹은 우측 앞 방향(± 30° or ± 60° azimuth)에 위치하였다.
소음 하 문장인지도 측정 시 보통대화레벨인 65 dB SPL에서 목표 문장을 제시할 수 있도록 사운드레벨미터(2230 Sound Level Meter; B&K, Virum, Denmark)를 이용하여 라우드스피커(Activer speaker; RadioEar, Middelfart, Denmark)의 볼륨을 조절하였고, 건청인 혹은 난청인이 비변동 소음 혹은 변동 소음 하에서 20~80% 가량 범위 내 한국어 Matrix 소음 하 문장인지를 보이는 SNR 범위를 고려하여(Jung et al., 2021; Jung et al., 2022) 건청인은 -20, -15, -10 dB SNR에서, 난청인은 0, 5, 10 dB SNR에서 소음 하 문장인지도(%)를 측정하였다. 실험을 시작하기 전에 연습 과정을 통해 대상자가 본 연구에서 사용할 변동 소음 혹은 비변동 소음 하에서 문장을 인지하고 따라말하는데 친숙해지는 세션을 가졌다. 실험 조건은 가장 듣기 쉬운 SNR 조건에서 점점 어려운 SNR 조건 순서로 진행하였고, 순서에 따른 이월(carryover) 효과를 고려하여 각 SNR 내에서 위치 분리, 소음 종류에 따른 듣기 조건은 무작위 순서로 제시하였다.
통계 분석
수집된 자료는 Statistical Product and Service Solution (SPSS 25.0 version; IBM Corp., Armonk, NY, USA)을 이용하여 분석하였다. 반복 측정된 삼원분산분석을 통해 그룹 내 변수(음원 간 위치 분리, 소음 종류, SNR)에 따른 주효과 및 상호작용을 NH와 HI의 소음 하 문장인지 결과에서 각각 분석하였다. Mauchly 구형성 검정 결과 구형성 가정에 위배되는 경우 Greenhouse-Geisser의 수정된 자유도와 F값을 보고하였으며, 주효과가 유의할 경우 Bonferroni 수정된 다중 비교를 시행하여 분석하였다. 모든 통계 분석은 유의 수준 0.05 미만에서 검증하였다.
RESULTS
건청인의 위치 분리 및 변동 소음의 이점
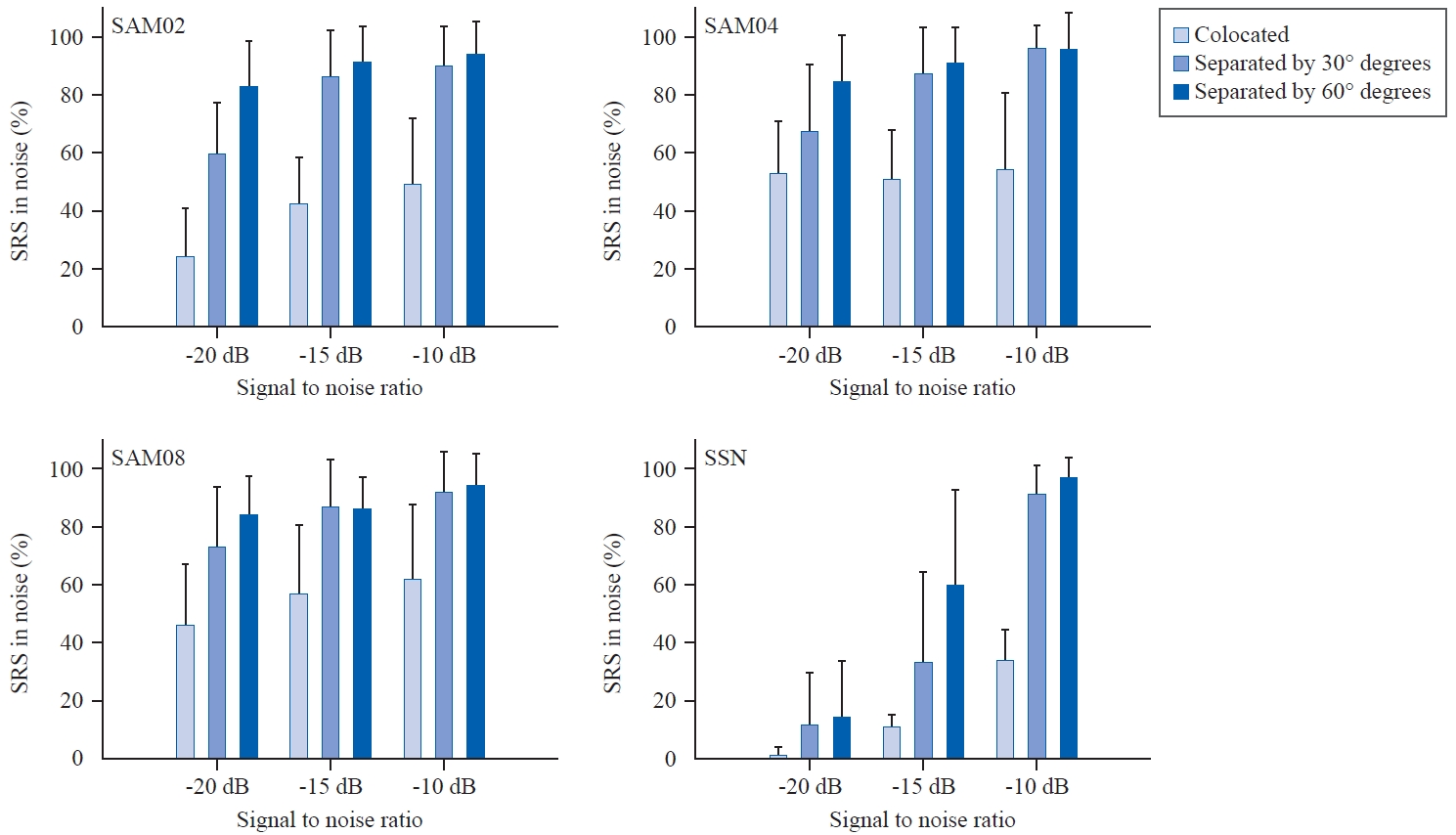
Figure 3은 음원 간 위치 분리 여부(정면에서 동시 제시, 30° 위치 분리, 60° 위치 분리), 소음 종류(SAM02, SAM04, SAM08, SSN), SNR (-20, -15, -10 dB SNR) 조건이 결합된 듣기 조건에서 측정한 건청인의 평균 소음 하 문장인지도를 보여준다. 반복측정된 삼원분산분석 결과, 음원의 위치 분리(F(1.37, 26.00) = 204.39), 소음 종류(F(3, 57) = 193.62), SNR (F(2, 38) = 162.33)에 따른 주효과 모두 유의하였다. Bonferroni 수정된 다중 비교 분석 결과, 세 가지 음원의 위치 분리 조건 중 정면에서 문장과 소음을 함께 제시한 조건(평균 40.25%)보다 30° 혹은 60° 위치 분리가 주어진 조건에서 건청인의 소음 하 문장인지도가 유의하게 더 높았고, 30° 위치 분리 조건(평균 72.75%)보다 60° 위치 분리 조건(평균 81.17%)에서 건청인의 소음 하 인지도가 유의하게 더 높았다. 본 연구에서 사용한 네 가지 소음 종류(SAM02, SAM04, SAM08, SSN) 중 비변동 소음인 SSN 소음 하 문장인지도가 다른 변동 소음 하 인지도보다 유의하게 더 낮았다(평균 39.17%). 변동 소음 세 가지(SAM02, SAM04, SAM08) 중 SAM02 소음 하 인지도(평균 68.67%)가 다른 변동 소음 하 결과보다 유의하게 낮았고, SAM04(평균 75.44%)과 SAM08 소음 하 인지도(평균 75.61%)에는 유의한 차이가 없었다. 마지막으로 세 가지 SNR 조건 중에는 -20 dB SNR의 조건(평균 50.00%)보다 -15 혹은 -10 dB SNR 조건에서 인지도가 유의하게 높았고, -15 dB SNR 조건(평균 65.08%)보다 -10 dB SNR 조건(평균 79.08%)에서 소음 하 인지도가 더 높았다.
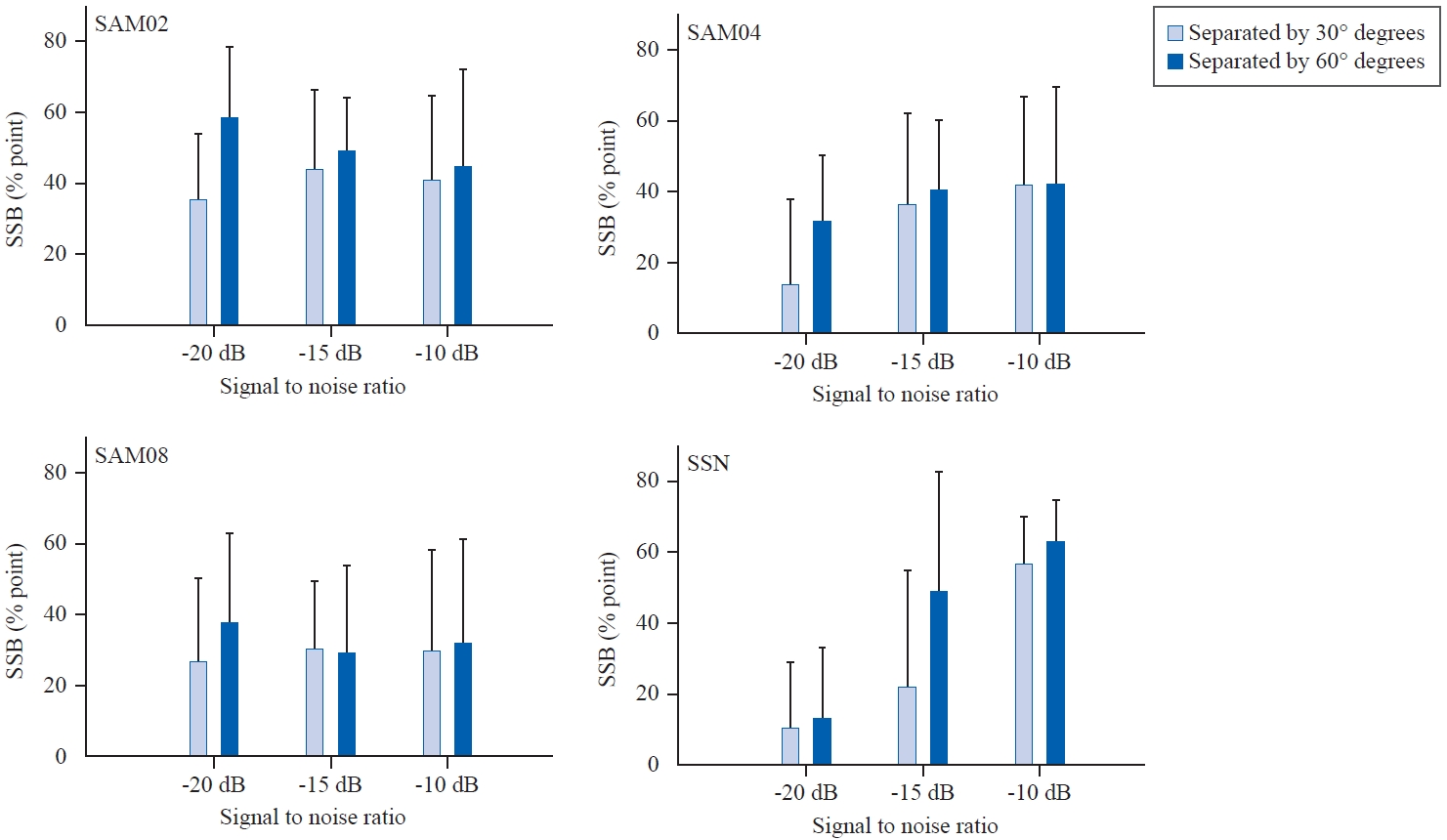
음원 간 위치 분리, 소음 종류, SNR 간 이원, 삼원상호작용이 모두 유의하였으므로 추가 분석을 시행하였다. 먼저 목표 문장과 소음의 위치 분리의 정도에 따라 건청인의 소음 하 어음인지가 얼마나 개선되는지 확인하기 위해 위치 분리된 조건에서의 인지도에서 정면에서 함께 제시된 조건에서의 인지도를 빼(score of spatially separated condition-score of colocated condition) SSB를 구하여 Figure 4에 나타내었다. 건청인에게 목표 문장과 SAM02 소음 간 30° 위치 분리가 주어졌을 때(Figure 4, top left panel), -20, -15, -10 dB SNR에서 평균 35.50%point (SD, 18.77), 44.00%point (SD, 22.80), 41.00%point (SD, 23.82) 증가하였고, 목표 문장과 SAM02 소음 간 60° 위치 분리가 주어졌을 때 동일 SNR 조건 순서대로 58.50%point (SD, 20.07), 49.00%point (SD, 15.53), 45.00%point (SD, 27.43) 증가하였다. 목표 문장과 SAM04 소음 간 30° 위치 분리가 주어졌을 때(Figure 4, top right panel), -20, -15, -10 dB SNR에서 평균 14.00%point (SD, 23.93), 36.50%point (SD, 25.60), 42.00%point (SD, 25.05) 증가하였고, 목표 문장과 SAM04 소음 간 60° 위치 분리가 주어졌을 때 동일 SNR 조건 순서대로 31.50%point (SD, 18.72), 40.50%point (SD, 19.86), 42.00%point (SD, 27.45) 증가하였다. 목표 문장과 SAM08 소음 간 30° 위치 분리가 주어졌을 때(Figure 4, bottom left panel), -20, -15, -10 dB SNR에서 평균 27.00%point (SD, 23.19), 30.50%point (SD, 19.05), 30.00%point (SD, 28.65) 증가하였고, 목표 문장과 SAM08 소음 간 60° 위치 분리가 주어졌을 때 동일 SNR 조건 순서대로 38.00%point (SD, 25.26), 29.50%point (SD, 24.38), 32.00%point (SD, 29.31) 증가하였다. 목표 문장과 SSN 소음 간 30° 위치 분리가 주어졌을 때(Figure 4, bottom right panel), -20, -15, -10 dB SNR 순서대로 평균 10.50%point (SD, 18.49), 22.00%point (SD, 33.34), 57.00%point (SD, 13.42) 증가하였고, 60° 위치 분리가 제시된 조건에서 위 SNR 순서대로 13.00%point (SD, 20.55), 49.00%point (SD, 34.01), 63.00%point (SD, 11.74) 증가하였다. 요약하면 네 가지 소음 종류 중 비변동 소음인 SSN 소음 제시 시, 30°나 60° 위치 분리에 의한 SSB 정도가 SNR 증가에 따라 가장 많이 증가하였음을 확인하였다. 건청인의 경우 전반적으로 소음 종류에 상관없이 30° 혹은 60° 위치 분리로 인한 혜택이 있었으며, 세 가지 SNR 조건 중 가장 듣기 어려운 조건인 -20 dB SNR에서 30° 보다 60° 위치 분리 혜택의 정도가 더 커지는 경향이 있었다. 네 가지 소음 종류 중 비변동 소음인 SSN 소음 제시 시 -20 dB SNR에서 SSB가 약 10%point 가량이었으나 -10 dB SNR에서 SSB가 약 60%point 가량으로 증가하여, 건청인이 가장 어려움을 보인 SSN 소음 상황에서 SNR 증가에 따라 SSB 정도가 급격히 증가하였다.
마지막으로, 비변동 소음보다 변동 소음이 제시된 조건에서 건청인의 소음 하 어음인지가 얼마나 향상하는지 확인하기 위해 변동 소음 하 어음인지도에서 비변동 소음 하 어음인지도를 빼(score of fluctuating masker condition-score of non-fluctuating masker condition) FMB를 구하여 Figure 5에 제시하였다. 건청인에게 정면 스피커에서 문장과 SAM02 소음을 함께 제시한 경우(Figure 5, top left panel), -20, -15, -10 dB SNR에서의 평균 FMB는 23.00%point (SD, 16.58), 31.00%point (SD, 17.44), 15.00%point (SD, 21.40), 30° 위치 분리가 제시된 경우 동일 SNR 순서대로 평균 FMB는 48.00%point (SD, 22.85), 53.00%point (SD, 32.62), -1.00%point (SD, 16.51), 60° 위치 분리가 제시된 경우 위와 동일한 SNR 순서대로 평균 FMB는 68.50%point (SD, 20.07), 31.00%point (SD, 34.63), -3.00%point (SD, 9.79)였다. 정면 스피커에서 문장과 SAM04 소음을 함께 제시한 경우(Figure 5, top right panel), -20, -15, -10 dB SNR에서의 평균 FMB는 52.00%point (SD, 17.04), 39.50%point (SD, 17.31), 20.00%point (SD, 29.38), 30° 위치 분리가 제시된 경우 동일 SNR 순서대로 평균 FMB는 55.50%point (SD, 25.23), 54.00%point (SD, 28.36), 5.00%point (SD, 11.00), 60° 위치 분리가 제시된 경우 동일 SNR 순서대로 평균 FMB는 70.50%point (SD, 22.59), 31.00%point (SD, 32.10), -1.00%point (SD, 7.88)였다. 정면 스피커에서 문장과 SAM08 소음이 함께 제시한 경우(Figure 5, bottom panel), -20, -15, -10 dB SNR에서의 평균 FMB는 45.00%point (SD, 22.36), 45.50%point (SD, 25.02), 28.00%point (SD, 25.87)였고, 30° 위치 분리가 제시된 경우 평균 FMB는 61.50%point (SD, 23.68), 54.00%point (SD, 31.19), 1.00%point (SD, 13.73), 60° 위치 분리가 제시된 경우 평균 FMB는 70.00%point (SD, 20.26), 26.00%point (SD, 29.81), -3.00%point (SD, 9.79)였다. 따라서 건청인의 경우 변동 소음의 변동률에 상관없이 듣기 어려운 -20 dB SNR 조건에서 FMB가 가장 컸고, -10 dB SNR에서 FMB가 가장 적었다. 가장 소음의 강도가 컸던 -20 dB SNR 조건의 경우, 위치 분리의 정도가 30° 에서 60°로 증가할수록 FMB가 더 커졌던 반면, 가장 듣기 쉬웠던 -10 dB SNR 조건의 경우 건청인이 비변동, 변동 소음 조건에서 이미 높은 인지도를 보여 30° 혹은 60° 위치 분리가 FMB에 크게 긍정적인 영향을 주지 않았다.
난청인의 위치 분리 및 변동 소음의 이점
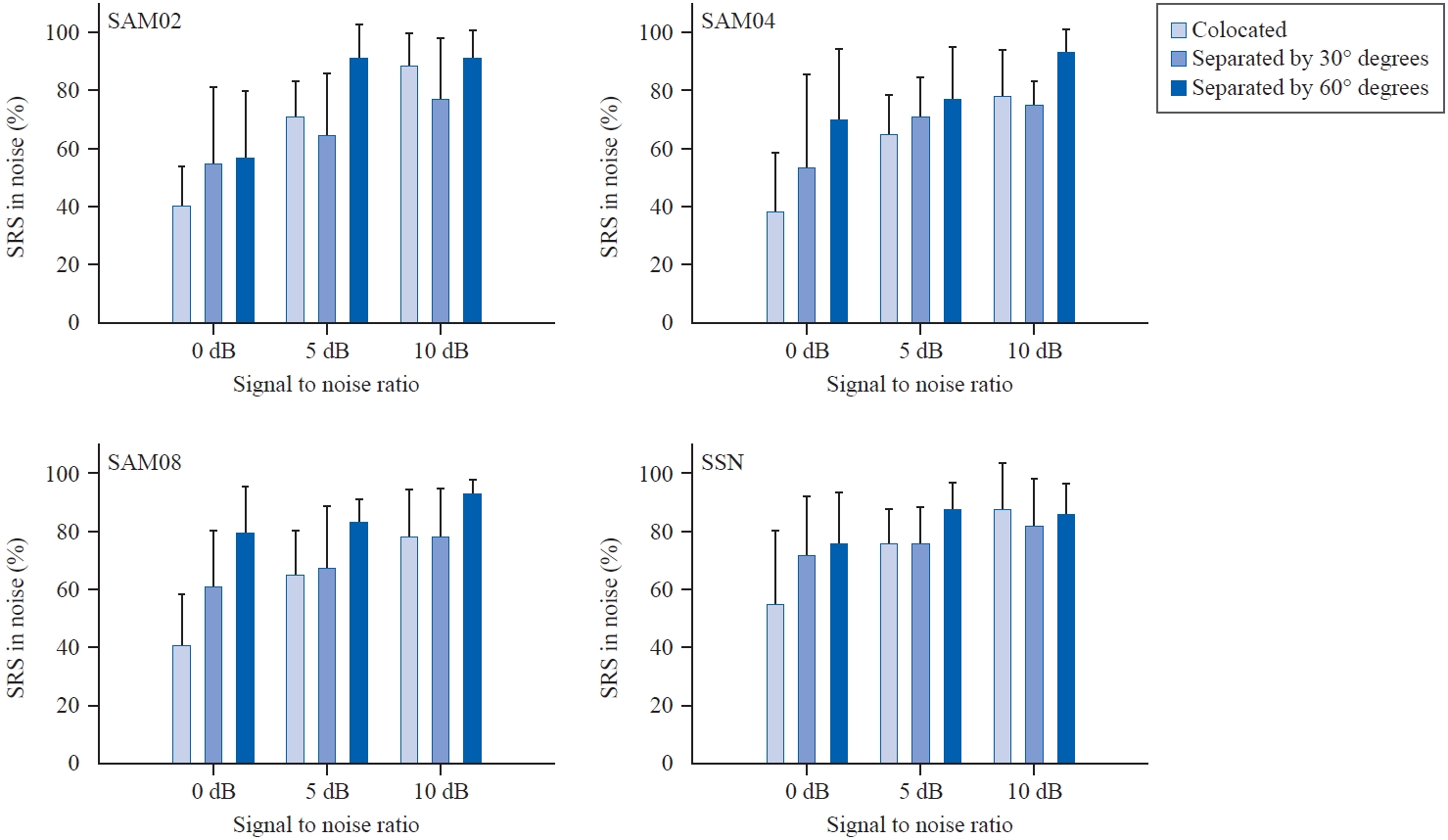
Figure 6은 음원 간 위치 분리, 소음 종류, SNR에 따른 난청인의 평균 소음 하 문장인지도를 보여준다. 반복 측정된 삼원분산분석 결과, 건청인과 마찬가지로 난청인의 경우에도 음원의 위치 분리(F(2, 18) = 18.98), 소음 종류(F(3, 27) = 7.18), SNR (F(1.17, 10.50) = 33.00)에 따른 주효과 모두 유의하였다. Bonferroni 수정된 다중 비교 분석 결과, 문장과 소음이 정면에서 함께 제시된 조건(평균 65.25%)과 30° 위치 분리 조건(평균 69.33%) 간 인지도는 유의하게 다르지 않았다. 정면에서 함께 제시된 조건 혹은 30° 위치 분리 조건에 비해 60° 위치 분리가 주어진 조건(평균 82.08%)에서의 소음 하 인지도가 유의하게 높았다. 세 가지 변동 소음(SAM02, SAM04, SAM08) 조건에서 측정 시 인지도는 유의하게 다르지 않았으며(평균 68~72%), SAM02 소음(평균 68.89%)과 SSN 소음 간 인지도(평균 77.67%)만 유의한 차이를 보였다. 마지막으로 0 dB SNR 조건(평균 58.17%)보다 5 혹은 10 dB SNR 조건에서, 5 dB SNR 조건(평균 74.58%)보다 10 dB SNR 조건(평균 83.92%)에서 인지도가 유의하게 더 높았다.
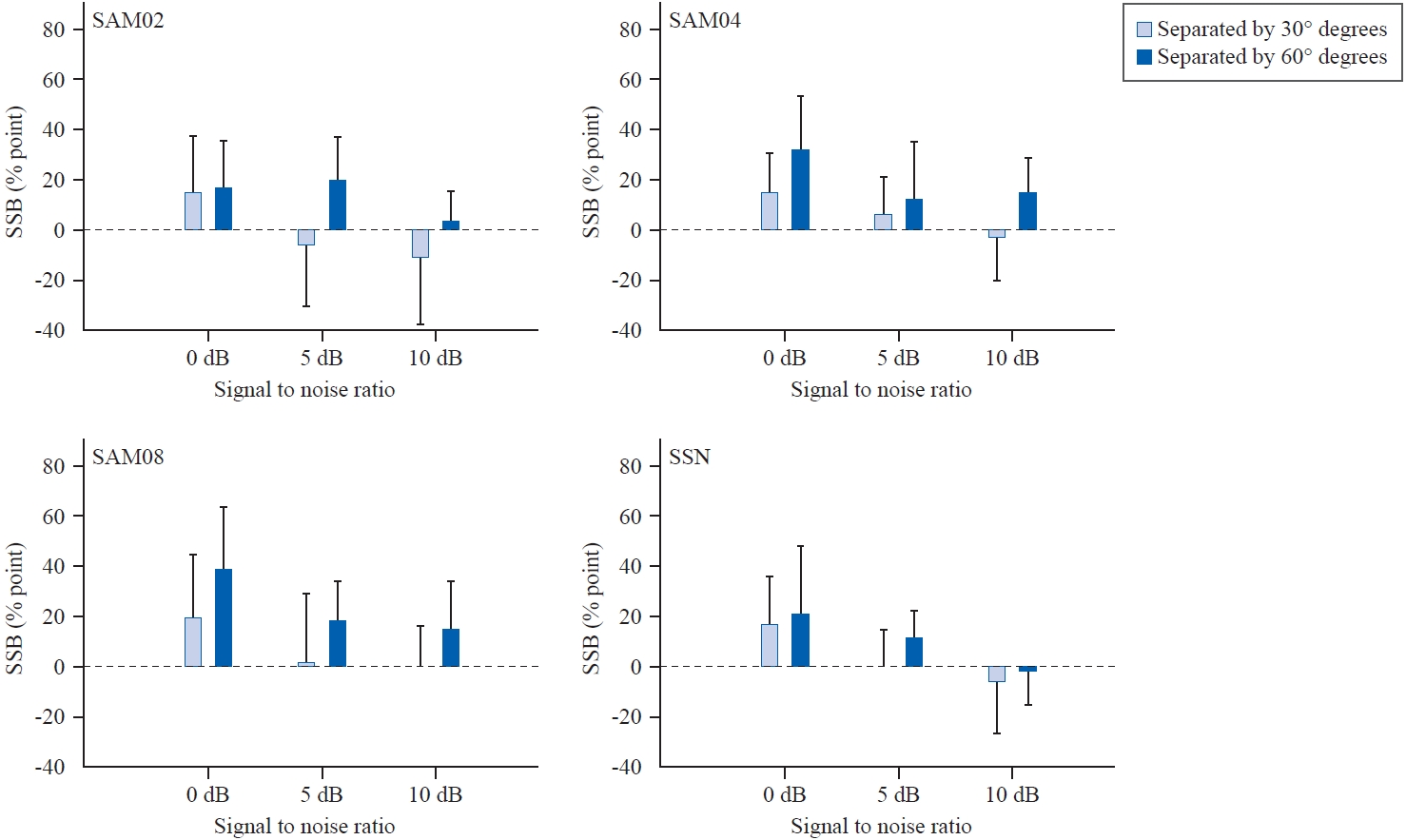
위치 분리와 SNR 변수 간 이원상호작용(F(4, 36) = 7.43), 소음 종류와 SNR 간 이원상호작용(F(3.25, 29.27) = 2.99) 외에 다른 상호작용은 유의하지 않았으므로, 아래의 추가 분석을 시행하였다. 먼저 목표 문장과 소음 간 위치 분리의 정도에 따라 난청인의 소음 하 어음인지가 얼마나 개선되는지 확인하기 위해 SSB를 구하여 Figure 7에 제시하였다. 난청인에게 목표 문장과 SAM02 소음 간 30° 위치 분리를 제시한 경우(Figure 7, top left panel), 0, 5, 10 dB SNR에서의 평균 SSB는 평균 15.00%point (SD, 22.24), -6.00%point (SD, 24.59), -11.00%point (SD, 26.85)였고, 목표 문장과 SAM02 소음 간 60° 위치 분리가 주어졌을 때 동일 SNR 조건 순서대로 평균 SSB는 17.00%point (SD, 18.89), 20.00%point (SD, 17.00), 3.00%point (SD, 12.52)였다. 목표 문장과 SAM04 소음 간 30° 위치 분리가 주어졌을 때(Figure 7, top right panel), 0, 5, 10 dB SNR에서의 SSB는 평균 15.00%point (SD, 15.81), 6.00%point (SD, 15.06), -3.00%point (SD, 17.03)였고, 60° 위치 분리가 주어졌을 때 동일 SNR 순서대로 평균 SSB가 32.00%point (SD, 21.50), 12.00%point (SD, 23.48), 15.00%point (SD, 13.54)였다. 목표 문장과 SAM08 소음 간 30° 위치 분리가 주어졌을 때(Figure 7, bottom left panel), 0, 5, 10 dB SNR에서의 SSB가 평균 20.00%point (SD, 24.94), 2.00%point (SD, 27.41), 0.00%point (SD, 16.33)였고, 60° 위치 분리가 주어졌을 때 동일 SNR 순서대로 평균 SSB가 39.00%point (SD, 24.70), 18.00%point (SD, 16.19), 15.00%point (SD, 19.58)였다. 목표 문장과 SSN 소음 간 30° 위치 분리가 제시된 조건에서(Figure 7, bottom right panel), 0, 5, 10 dB SNR에서의 평균 SSB는 17.00%point (SD, 18.89), 0.00%point (SD, 14.91), -6.00%point (SD, 20.66)였고, 60° 위치 분리가 제시된 조건에서 위 SNR 순서대로 평균 SSB가 21.00%point (SD, 27.26), 12.00%point (SD, 10.33), -2.00%point (SD, 13.17)였다. 따라서 난청인의 경우 대체로 30° 위치 분리보다 60° 위치 분리 시 SSB 정도가 더 컸으며, 세 가지 SNR 중 가장 듣기 어려운 조건인 0 dB SNR에서 SSB 정도가 더 큰 편이었다.
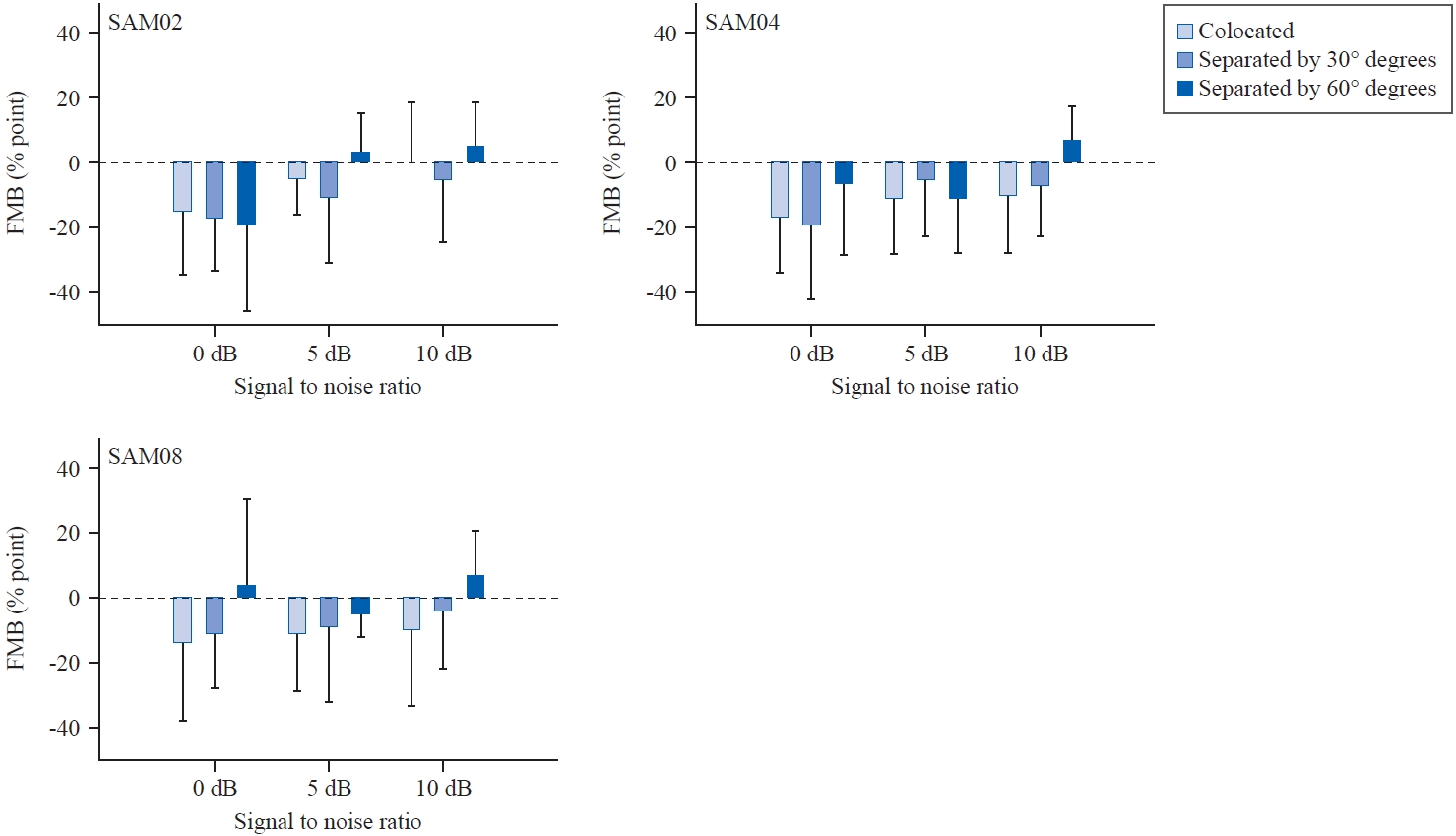
마지막으로 비변동 소음보다 변동 소음이 제시된 조건에서 난청인의 소음 하 어음인지가 어떻게 변화했는지 확인하기 위해 FMB를 구하여 Figure 8에 나타내었다. 난청인에게 정면 스피커에서 문장과 SAM02 소음을 함께 제시한 경우(Figure 8, top left panel), 0, 5, 10 dB SNR에서의 평균 FMB는 -15.00%point (SD, 19.58), -5.00%point (SD, 10.80), 0.00%point (SD, 18.26)였고, 30° 위치 분리가 제시된 경우 동일 SNR 순서대로 평균 FMB는 -17.00%point (SD, 16.36), -11.00%point (SD, 19.69), -5.00%point (SD, 20.14)였고, 60° 위치 분리가 제시된 경우 위와 동일한 SNR 순서대로 평균 FMB는 -19.00%point (SD, 26.85), 3.00%point (SD, 12.52), 5.00%point (SD, 13.54)였다. 정면 스피커에서 문장과 SAM04 소음을 함께 제시한 경우(Figure 8, top right panel), 0, 5, 10 dB SNR에서의 평균 FMB는 -17.00%point (SD, 17.03), -11.00%point (SD, 17.29), -10.00%point (SD, 17.64)였고, 30° 위치 분리가 제시된 경우 동일 SNR 순서대로 평균 FMB는 -19.00%point (SD, 23.31), -5.00%point (SD, 17.80), -7.00%point (SD, 15.67)였고, 60° 위치 분리가 제시된 경우 평균 FMB는 -6.00%point (SD, 22.71), -11.00%point (SD, 16.63), 7.00%point (SD, 10.59)였다. 정면 스피커에서 문장과 SAM08 소음을 함께 제시한 경우(Figure 8, bottom panel), 0, 5, 10 dB SNR에서의 평균 FMB는 -14.00%point (SD, 24.13), -11.00%point (SD, 17.92), -10.00%point (SD, 23.09)였고, 30° 위치 분리가 제시된 경우 평균 FMB는 -11.00%point (SD, 17.29), -9.00%point (SD, 23.31), -4.00%point (SD, 18.38)였고, 60° 위치 분리가 제시된 경우 평균 FMB는 4.00%point (SD, 26.33), -5.00%point (SD, 7.07), 7.00%point (SD, 13.37)였다. 난청인의 경우 대부분의 조건에서 비변동 소음 하 인지도가 변동 소음 하 인지도보다 더 높았으므로 FMB를 보이지 않는 경우가 많았으며, 여러 조건 중 가장 소음 강도가 작은 10 dB SNR에서 60° 위치 분리가 주어졌을 때 5~7%point 가량의 FMB를 관찰할 수 있었다.
DISCUSSION
본 연구에서는 목표 어음과 소음 간 위치 분리, 소음의 변동 특성에 의해 건청인과 난청인의 소음 하 어음인지가 향상하는지, 향상 정도가 SNR에 따라 영향을 받는지 확인하였다. 먼저 음원 간 위치 분리 여부에 따른 소음 하 어음인지 결과를 살펴보면, 건청인의 경우 목표 화자와 배경 소음이 정면에서 동시에 제시되는 조건보다 음원 간 30°의 위치 분리만 주어져도 소음 하 어음인지가 개선되었다. 난청인의 경우 음원 간 위치 분리가 30°일 경우에는 큰 혜택을 보이지 않았으나 위치 분리가 60° 이상일 때 소음 하 인지도가 유의하게 개선되었으며, 여러 조건 중 가장 듣기 어려운 조건인 0 dB SNR에서 SSB 정도가 가장 컸다. 즉, 난청인의 경우 0 dB SNR과 같이 듣기 어려운 상황에서는 소음의 종류에 상관없이 음원 간 위치 분리가 60° 이상이 되어야 소음 하 어음인지에 도움이 되었다. 본 연구와 마찬가지로 Srinivasan et al.(2016)은 노인 난청군의 경우 음원 간 위치 분리가 30° 주어져도 큰 혜택을 보이지 않았던 반면, 건청인은 음원 간 위치 분리가 2°일 때도 긍정적인 위치 분리 혜택를 보였다고 하였다.
음 종류에 따라 본 연구의 SSB를 살펴보면 건청인의 경우 변동 소음보다는 비변동 소음(SSN) 하에서 SNR 증가에 따라 SSB 정도가 급격히 증가함을 확인하였다. 비변동 소음은 음향차폐(energetic masking)를 주로 제공하므로 비변동 소음과 목표 어음이 정면에서 동시에 제시되었을 때 음향차폐의 주된 영향으로 저조한 소음 하 인지를 보이다가, SNR이 증가하면서 음향차폐도 비례적으로 줄어들어 건청인의 SSB가 급격하게 증가한 것으로 생각한다. 난청인의 경우 건청인에 비해 SSB 정도가 적었을 뿐 아니라, 대부분의 소음 종류에서 SNR 증가에 따라 SSB가 감소하는 추세를 보였다. Marrone et al.(2008) 역시 건청군에 비해 난청군이 더 저조한 SSB를 보였으며, 난청군의 연령, 청력 상태 혹은 반향 여부 등과 같은 실험 조건이 SSB에 영향을 미칠 수 있다고 하였다. Bronkhorst & Plomp(1992)은 난청인이 음원의 위치 분리에 의한 혜택을 보이긴 하였으나 실험 조건(소음의 개수, 위치 등) 내 변수의 영향을 많이 받았다고 하였다. Yost(2017)은 배경소음으로 경쟁 화자 수를 달리하여 SSB 정도를 측정한 결과 경쟁 소음 화자 수가 2명에서 6명으로 증가할수록 SSB 정도가 감소하였다고 보고하였다. Arbogast et al.(2005)은 건청인보다 난청인의 SSB 정도가 더 적었으나 정보차폐(informational masking)가 주를 이루는 소음 상황에서도 난청인은 긍정적인 SSB를 보였다고 하였다. 본 연구와 선행 연구의 결과들을 종합하면, 위치 분리로 인한 혜택은 두영 효과(head shadow effect), 양이에 전달되는 신호의 시간차(interaural time difference) 혹은 강도차(interaural level difference) 단서 등에 의해 일부 영향을 받으며, 배경소음의 종류가 변동 소음 혹은 경쟁 화자의 어음으로 음향차폐와 정보차폐를 함께 제공할 경우 주어진 여러 단서에 따라 보다 복잡한 상호작용을 가져 건청인 혹은 난청인의 위치 분리 혜택을 증가 혹은 감소시킬 수 있겠다(Hawley et al., 2004; Kidd et al., 1998; Marrone et al., 2008, Oh et al., 2022; Yost, 2017).
본 연구에서는 소음 내 변동 특성에 따라 비변동 소음보다 변동 소음 하 어음인지가 더 향상하는지 확인하였고, 건청인의 경우 대부분의 듣기 조건에서 긍정적인 FMB를 보였으나 난청인은 전반적으로 긍정적인 FMB를 보이지 않았다. 본 연구에서 제작한 정현파 진폭 변조된(sinusoidally amplitudemodulated) 변동 소음 속에서 어음을 인지할 때 건청인은 목표 어음의 정보를 엿보는 기회(glimpsing)를 가져 비변동 소음보다 변동 소음 하 문장인지가 더 향상하였던 것이다. Bronkhorst & Plomp(1992), Eisenberg et al.(1995), Gustafsson & Arlinger(1994) 등 다양한 연구에서 본 연구와 유사하게 난청인은 건청인에 비해 유의하게 저조한 FMB를 보였다고 하였고, 이는 난청 성인뿐 아니라 난청 아동군 혹은 보청기 착용 아동에게도 관찰된 바 있다(Brennan et al., 2016; Hall et al., 2012).
FMB 정도를 위치 분리 정도, 변동 특성 등에 따라 살펴보면, 건청인의 경우 음향차폐가 큰 -20 dB SNR 조건에서 위치 분리의 정도가 30°에서 60°로 증가할수록 FMB가 점차 증가한 반면, 비교적 더 듣기 쉬운 조건인 -10 dB SNR에서 건청인이 이미 90% 이상의 높은 인지도를 보이는 천장 효과(ceiling effect) 때문에 30° 혹은 60° 위치 분리가 건청인의 FMB에 크게 영향을 주지 않았다. 본 연구에서는 배경소음으로 2, 4, 8 Hz의 변동률을 가지고 정현 곡선을 따라 진폭이 변조되는 소음을 변동 소음으로 제시하였다. 건청인의 경우 2 Hz의 변동 소음보다 4 Hz 혹은 8 Hz의 변동률을 가진 소음에서 인지도가 비교적 더 높았으나, 난청인의 경우 변동률에 따라 인지도가 유의하게 다르지 않아 변동률에 상관없이 변동 소음으로부터 glimpsing 기회를 잘 사용하지 못함을 알 수 있었다. Jensen & Bernstein(2019)는 건청인의 경우 4, 8 Hz 변동률을 가진 변동 소음을 제시하였을 때 FMB가 가장 컸으며, 난청인 역시 변동률에 따라 FMB가 달랐다고 보고하였다. Fogerty et al.(2018) 역시 4, 8 Hz의 변동률을 가졌을 때 혜택의 정도가 가장 컸으며, 불규칙적인 무작위 변조보다 규칙적으로 변동되는 특성을 가진 소음 하에서 더 우수한 인지도를 보였다고 하였다. Francart et al.(2011)은 변동 소음 내 경쟁 어음의 의미는 없지만 어음의 변동 특성을 가진 International Collegium of Rehabilitative Audiology (ICRA) 소음과 International Speech Test Signal (ISTS) 소음을 사용하여 FMB를 비교한 결과, 난청인은 건청인에 비해 비교적 적은 FMB를 보였다. 따라서 청자의 FMB 측정 시 변동 비율, 깊이뿐 아니라 변동 방법 등 다양한 변동 소음 특성에 따라 FMB의 정도에 차이가 있을 수 있겠다.
본 연구와 선행 연구의 결과들을 종합하면 건청인은 비변동 소음보다 변동 소음 하에서 대체로 더 우수한 인지도를 보여 FMB가 명확하게 관찰되었고, 난청인은 변동 소음이 제시되었을 때 오히려 소음 하 어음인지도가 더 낮아져 FMB가 현저히 감소하거나 긍정적인 FMB를 관찰할 수 없었다. 난청인이 이러한 경향을 보인 것은 변동 소음 조건에서 어음인지 시 소음의 강도가 순간적으로 감소하는 부분이 어음인지의 ‘cue’로 받아들여지는 것이 아니라, 시간에 따라 계속적으로 바뀌는 변동 특성 자체가 목표 어음에 선택적으로 집중하는 것을 방해하였기 때문으로 보인다. 실제로 본 연구에 참여한 대상자들은 변동 소음의 강도 변화가 어음인지에 혜택을 주는 것이 아니라 오히려 목표 문장에 집중하여 끝까지 듣는 것을 방해하는 요소가 된다고 하였다. 여러 연구자들은 난청인이 저조한 FMB를 보이는 데 난청인의 청력 상태 그리고 그 외 다양한 요인이 영향을 준다고 설명하였다. Summers & Molis(2004)는 건청인에 비해 난청인에게는 FMB가 거의 관찰되지 않았으며, 이러한 결과는 단순히 난청인의 가청 정도(audibility) 외에 역치 이상의 처리능력(suprathreshold processing)에 의해 설명해야 한다고 주장하였다. George et al.(2006) 역시 난청인의 청력 역치보다는 역치 이상의 시간해상 능력(temporal resolution) 등이 FMB 정도에 영향을 준다고 하였다. Fogerty et al.(2015)은 건청 노인과 난청 노인을 대상으로 변동 잡음 혜택이 문장 내 자음과 모음 중 어느 부분에서 발생하는지를 확인하였다. 분석 결과 변동 잡음 혜택은 문장 내 주로 모음으로부터 기인한 것으로 밝혔고, 난청 노인이 비교적 적은 FMB를 보이는 이유는 시간적 처리능력의 결함 때문이라고 설명하였다.
본 연구는 여러 가지 제한점을 가지고 있다. 첫 번째는 난청인 대상자 수가 10명이었다는 점이다. 난청인 대상자의 경우 개인 차이가 많음을 고려하였을 때 추후 연구에서 보다 많은 대상자를 통한 검증이 필요하다. 또한 본 연구에 참여한 난청인은 대부분은 60~70대로 난청 대상자의 연령이 소음 하 문장인지에 영향을 미쳤을 것이다. 다수의 선행 연구에서 노화가 소음 하 어음인지에 부정적인 영향을 미친다고 보고하였으므로(Dubno et al., 2003; Irsik et al., 2022; Marrone et al., 2008), 추후 연구 설계 시 건청 노인을 대상군으로 추가로 모집하거나 연령 요인을 통계적으로 고려하는 분석을 진행하는 것이 필요하겠다. 두 번째는 본 연구에서 정현파 곡선과 100% 변동 깊이(modulation depth) 특성을 가진 변동 소음만을 사용하였으므로, 경쟁 어음과 같은 정보차폐의 영향을 확인할 수 없었다. Jensen & Bernstein(2019)는 실험에 다양한 소음 종류(비변동 소음, 4 Hz와 32 Hz의 변동률을 보이는 변동 소음, 경쟁 화자가 말하는 어음)를 사용하여 건청인과 난청인의 FMB를 측정한 결과, 변동률과 정보차폐 여부에 따라 난청인의 FMB는 달랐다고 하였다. Oh et al.(2022)은 경쟁 화자의 어음을 배경소음으로 할 경우 목표 화자와 경쟁 화자 간 성별 차이와 위치 분리 모두 소음 하 어음인지에 직접적인 영향을 주었다고 하였다. 따라서 소음 하 어음인지 시 소음 내 변동 특성, 정보차폐 여부 등에 따라 FMB 정도가 달라질 수 있으니 이를 고려하여 연구 및 임상 평가를 설계해야겠다.
본 연구에 참여한 난청군은 조용한 상황에서 문장인지도가 평균 90% 이상으로 소음이 없는 경우 의사소통에 큰 어려움이 없는 대상자였다. 난청인은 변동 소음 하에서 건청인과 달리 변동 특성을 이용하는 긍정적인 FMB를 관찰할 수 없었고, 난청인의 SSB 역시 건청인에 비해 적었다. 다양한 선행 연구에서 난청인의 SSB 혹은 FMB를 측정하여 난청인의 평가 및 재활 시 활용하는 것을 권장했으나, 청각 관련 임상에서 위치 분리나 변동 소음을 활용한 어음인지 평가가 활발히 이루어지지 않고 있다. Francart et al.(2011)은 검사 소요 시간이 크게 문제가 되지 않는다면 ICRA 혹은 ISTS 소음과 같은 변동 소음을 소음 하 어음인지 평가 시 사용할 것을 권고하였다. King et al.(2020) 역시 연구 목적뿐 아니라 임상에서도 청각평가 시 SSB를 측정하여 난청인이 일상적으로 겪는 소음 하 의사소통의 어려움을 예측하는 게 필요하다고 보고하였다. 본 연구의 결과를 고려하였을 때 기존 임상에서 주로 시행하는 조용한 상황에서의 기초 청각 평가만으로는 난청인의 SSB, FMB 등을 평가 및 예측하는데 한계가 있음을 확인하였다. 따라서 국내에서도 난청인의 위치 분리 혜택, 변동 소음 혜택을 측정할 수 있는 평가 방법과 위치 분리 혜택 정도를 증가시킬 수 있는 공간청능훈련(spatial auditory training) 프로토콜(Coudert et al., 2023; Valzolgher et al., 2023a; Valzolgher et al., 2023b)을 구축할 수 있도록 지속적인 연구가 필요하겠다.